· 17 min read
Clean architecture for Android with Kotlin: a pragmatic approach for starters

Clean architecture is a topic that never gets old in the Android world, and from the comments and questions I receive, I feel it’s still not very clear.
I know there are tens (or probably hundreds) of articles related to clean architecture, but here I wanted to give a more pragmatic/simplistic approach that can help in the first incursion to the clean architecture. That’s why I’ll be omitting concepts that may feel unavoidable to architecture purists.
My only goal here is that you understand what I consider the main (and most complicated) topic in clean architecture: the dependency inversion. Once you get that, you can go to other articles to fill in the little gaps that I may have left outside.
Clean architecture: why should I care?
Even if you decide not to use architectures in your Apps, I think that learning them is really interesting, because they will help you understand important programming and OOP concepts.
Architectures allow decoupling different units of your code in an organized manner. That way the code gets easier to understand, modify and test.
But complex architectures, like the pure clean architecture, can also bring the opposite effect: decoupling your code also means creating lots of boundaries, models, data transformations… that may end up increasing the learning curve of your code to a point where it wouldn’t be worth it.
So, as you should do with everything you learn, try it in the real world and decide what level of complexity you want to introduce. It will depend on the team, the size of the App, the kind of problems it solves…
So let’s start! First, let’s define the layers that our App will use.
The layers for a clean architecture
You can see different approaches from different people. But for simplicity, we’re sticking to 5 layers (it’s complex enough anyway 😂):
1. Presentation
it’s the layer that interacts with the UI. You will probably see it divided into two layers in other examples, because you could technically extract everything but the framework classes to another layer. But in practice, it’s hardly ever useful and it complicates things.
This presentation layer usually consists of Android UI (activities, fragments, views) and presenters or view models, depending on the presentation pattern you decide to use. If you go for MVP, I have an article where I explain it in deep (and I would like to write one about MVVM soon).
2. Use cases
It’s usually called interactors too. These are mainly the actions that the user can trigger. Those can be active actions (the user clicks on a button) or implicit actions (the App navigates to a screen).
If you want to be extra-pragmatic, you can even avoid this layer. I like it because it’s usually the point where I switch threads. From this point, I can run everything else on a background thread and forget about being careful with the UI thread. I like it because I don’t need to wonder anymore if something is running in the UI thread or a background thread.
3. Domain
Also known as business logic. These are the rules of your business.
It contains all the business models. For instance, in a movies App, it could be the Movie class, the Subtitle class, etc.
Ideally, it should be the biggest layer, though it’s true that Android Apps usually tend to just draw an API in the screen of a phone, so most of the core logic will just consist of requesting and persisting data.
4. Data
In this layer, you have an abstract definition of the different data sources, and how they should be used. Here, you will normally use a repository pattern that, for a given request, it’s able to decide where to find the information.
In a typical App, you would save your data locally and recover it from the network. So this layer can check whether the data is in a local database. If it’s there and it’s not expired, return it as a result, and otherwise ask the API for it and save it locally.
But data not only comes from a request. You may, for instance, need data from the device sensors, or from a BroadcastReceiver (though the data layer should never know about this concept! We’ll see it later)
5. Framework
You can find this layer called in many different ways. It basically encapsulates the interaction with the framework, so that the rest of the code can be agnostic and reusable in case you want to implement the same App in another platform (a real option nowadays with Kotlin multi-platform projects!). With framework I’m not only referring to the Android framework here, but to any external libraries that we want to able to change easily in the future.
For instance, if the data layer needs to persist something, here you could use Room to do it. Or if it needs to do a request, you would use Retrofit. Or it can access the sensors to request some info. Whatever you need!
This layer should be as simple as possible, as all the logic should be abstracted into the data layer.
Remember! These are the suggested layers, but some of them can be merged. You could even just have three layers: presentation - domain - framework. This probably can’t be strictly called clean architecture, but I honestly don’t care about namings. I’ll leave 5 layers because it helps me explain the next point, which is the important one.
Interaction between layers
So this is the hardest part to explain and understand. I’ll try to be as clear as possible because I think this is also the most important point if you want to understand the clean architecture. But feel free to write me if you don’t understand anything, and I’ll update this text.
When you think of a logical way of interaction, you’d say that the presentation uses the use cases layer, which then will use the domain to access the data layer, which will finally use the framework to get access to the requested data. Then this data flies back to the layer structure until it reaches the presentation layer, which updates the UI. This would be a simple graph of what’s happening:
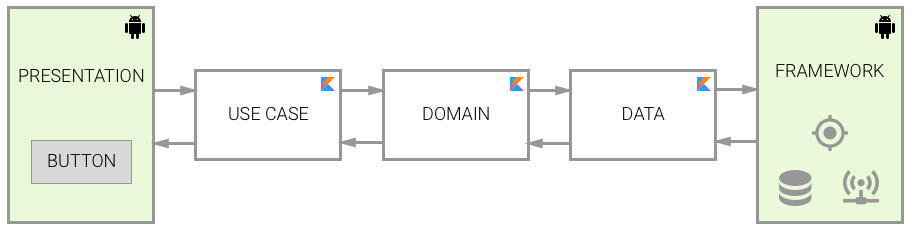
As you can see, the two limits of the flow depend on the framework, so they require using the Android dependency, while the rest of the layers only require Kotlin. This is really interesting if you want to divide each layer into a separate submodule. If you were to reuse the same code for (let’s say) a Web App, you’d just need to reimplement the presentation and framework layers.
But don’t mix the flow of the App with the direction of the dependencies between layers. If you’ve read about clean architecture before, you probably saw this graph:
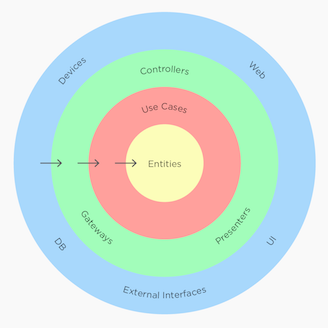
Which is a bit different from the previous image. Namings are also different, but I reformulate this in a minute. Basically, the clean architecture says that we have outer and inner layers, and that the inner layers shouldn’t know about the outer ones. This means that an outer class can have an explicit dependency from an inner class, but not the other way round.
Let’s recreate the above graph with our own layers:
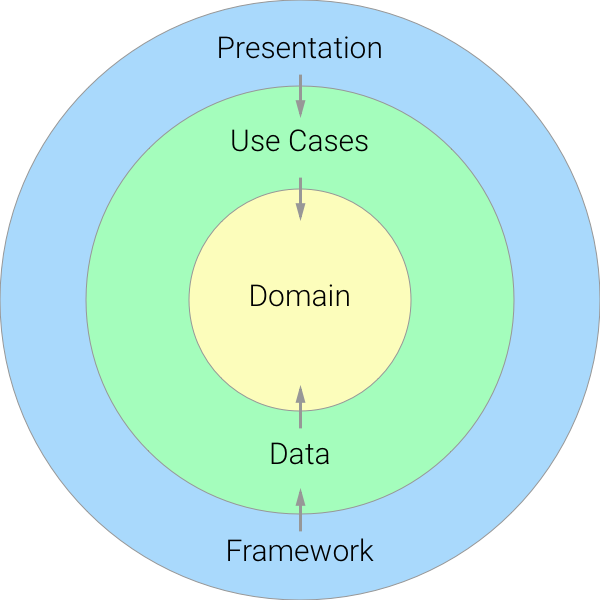
So from the UI to the domain, everything is quite simple, right? The presentation layer has a Use Case dependency, and it’s able to call to start the flow. Then the Use Case has a dependency on the domain.
But the problems come we go from the inside to the outside. For instance, when the data layer needs something from the framework. As it’s an inner layer, the Data layer doesn’t know anything about the external layers, so how can it communicate with them?
Pay attention, here it comes an important concept.
Dependency Inversion Principle
If you have learned about SOLID principles, you may have read about Dependency Inversion. Pero, como con muchos de estos conceptos, es posible que no hayas entendido cómo aplicarlo. La inversión de dependencias es la “D” de SOLID, y esto es lo que dice:
A. Los módulos de alto nivel no deben depender de los módulos de bajo nivel. Ambos deben depender de abstracciones. B. Las abstracciones no deben depender de los detalles. Los detalles deben depender de las abstracciones.
Así que, sinceramente, esto no me dice demasiado en mi trabajo diario. Pero con nuestro ejemplo, es más fácil de entender.
Un ejemplo de inversión de dependencias
Supongamos que tenemos un DataRepository en la capa de datos que requiere un RoomDatabase para recuperar algunos datos persistidos. El primer enfoque sería tener algo como esto. Esta es nuestra RoomDatabase:
class RoomDatabase {
fun requestItems(): List<Item> { ... }
}
Y el DataRepository lo instanciaría y usaría:
class DataRepository {
private val roomDatabase = RoomDatabase()
fun requestItems(): List<Item> {
val items = roomDatabase.requestItems()
...
return result
}
}
Pero esto no es posible! La capa de datos no conoce las clases en Framework porque es una capa interna.
Así que el primer paso es hacer un inversion de control (no mezclar con inversión de dependencias, no son lo mismo), lo que significa que en lugar de instanciar la clase nosotros mismos, dejamos que se proporcione desde afuera (a través del constructor):
class DataRepository(private val roomDatabase: RoomDatabase) {
fun requestItems(): List<Item> {
val items = roomDatabase.requestItems()
...
return result
}
}
Fácil, ¿verdad? Pero aquí es donde necesitamos hacer la inversión de dependencias. En lugar de depender de la implementación específica, vamos a depender de una abstracción (una interfaz). Así que el módulo de datos tendrá la siguiente interfaz:
interface DataPersistence {
fun requestItems(): List<Item>
}
Ahora el DataRepository puede usar solo la interfaz (que está en su misma capa):
class DataRepository(private val dataPersistence: DataPersistence) {
fun requestItems(): List<Item> {
val items = dataPersistence.requestItems()
...
return result
}
}
Y como la capa de framework puede usar la de datos, puede implementar esa interfaz:
class RoomDatabase : DataPersistence {
override fun requestItems(): List<Item> { ... }
}
El único punto restante sería cómo proporcionar la dependencia al DataRepository. Eso se hace usando inyección de dependencias. Las capas externas se encargarán de ello.
No entraré en detalles sobre la inyección de dependencias en este artículo, ya que no quiero añadir muchos conceptos complejos. Tengo un conjunto de artículos hablando sobre ello y sobre Dagger si quieres saber más.
Construyendo un ejemplo
Primero que nada, puedes encontrar el ejemplo completo en este repositorio. Voy a omitir algunos detalles, así que asegúrate de ir allí, clonarlo y jugar con él.
Así que todo esto es muy bueno, pero necesitas ponerlo en práctica si quieres entenderlo.
Para ello, estamos creando una App que permitirá solicitar la geolocalización actual gracias a un botón y mantener un registro de las ubicaciones previamente solicitadas, mostrándolas en una lista.
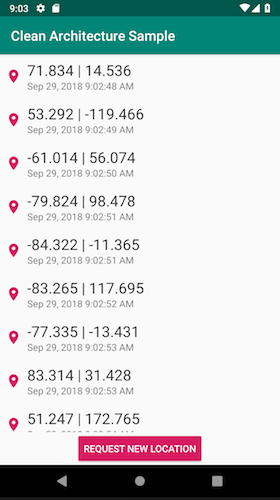
Construyendo un proyecto de muestra
El proyecto consistirá en un conjunto de 5 módulos.
Para simplificar, solo estoy creando 4:
- app: será el único proyecto que use el framework de Android, que incluirá las capas de Presentación y Framework.
- usecases: será un módulo de Kotlin (no necesita el framework de Android).
- domain: otro módulo de Kotlin.
- data: un módulo de Kotlin también.
Podrías perfectamente hacer todo en el mismo módulo y usar paquetes. Pero es más fácil no violar el flujo de dependencia si haces así. Así que lo recomiendo si estás comenzando.
Crea un nuevo proyecto, que automáticamente creará el módulo app, y luego crea los módulos Java extra:
No hay una opción de “Kotlin Library”, así que necesitarás agregar el soporte de Kotlin más tarde.
La capa de dominio
Necesitamos una clase que represente la ubicación. En Android, ya tenemos una clase de Location. Pero recuerda que queremos dejar los detalles de implementación en las capas externas.
Imagina que quieres usar este código mañana para una App web escrita en KotlinJS. Ya no tendrás acceso a las clases de Android.
Así que aquí está la clase:
data class Location(val latitude: Double, val longitude: Double, val date: Date)
Si has leído sobre esto antes, la arquitectura limpia pura tendría una representación del modelo por capa, lo que en nuestro caso implicaría tener una clase
Locationen cada capa. Luego, usarías transformaciones de datos para convertirla a través de diferentes capas. Eso hace que las capas estén menos acopladas, pero también que todo sea más complejo. En este ejemplo, solo lo haré cuando sea estrictamente necesario.
Eso es probablemente todo lo que necesitas en esta capa para este ejemplo simple.
La capa de datos
La capa de datos generalmente se modela utilizando repositorios que tienen acceso a los datos que necesitamos. Podemos tener algo como esto:
class LocationsRepository {
fun getSavedLocations(): List<Location> { ... }
fun requestNewLocation(): List<Location> { ... }
}
Tiene una función para obtener las ubicaciones antiguas solicitadas, y otra función para solicitar una nueva.
Como puedes ver, esta capa está utilizando la capa de dominio. Una capa exterior puede usar las capas internas (pero no al revés). Para hacer eso, necesitas agregar una nueva dependencia al archivo build.gradle del módulo:
dependencies {
implementation project(':domain')
...
}
El repositorio va a usar un par de fuentes:
class LocationsRepository(
private val locationPersistenceSource: LocationPersistenceSource,
private val deviceLocationSource: DeviceLocationSource
)
Una de ellas tiene acceso a las ubicaciones persistidas, y la otra a la ubicación del dispositivo.
Y aquí es donde sucede la magia de la inversión de dependencias. Estas dos fuentes son interfaces:
interface LocationPersistenceSource {
fun getPersistedLocations(): List<Location>
fun saveNewLocation(location: Location)
}
interface DeviceLocationSource {
fun getDeviceLocation(): Location
}
Y la capa de datos no sabe (y no necesita saber) cuál es la implementación real de estas interfaces. Las ubicaciones de persistencia y de dispositivo necesitan ser gestionadas por el framework específico del dispositivo. Nuevamente, volviendo al ejemplo de KotlinJS, una App web lo implementaría muy diferente a una App de Android.
Ahora, el LocationsRepository puede usar estas fuentes sin conocer la implementación final:
fun getSavedLocations(): List<Location> = locationPersistenceSource.getPersistedLocations()
fun requestNewLocation(): List<Location> {
val newLocation = deviceLocationSource.getDeviceLocation()
locationPersistenceSource.saveNewLocation(newLocation)
return getSavedLocations()
}
La capa de casos de uso
Esta suele ser una capa muy simple, que solo convierte las acciones del usuario en interacciones con las demás capas internas. En nuestro caso, tenemos un par de casos de uso:
GetLocations: devuelve las ubicaciones que ya han sido registradas por la App.RequestNewLocation: le dirá alLocationsRepositoryque busque la ubicación actual.
Estos casos de uso tendrán una dependencia del LocationsRepository:
class GetLocations(private val locationsRepository: LocationsRepository) {
operator fun invoke(): List<Location> = locationsRepository.getSavedLocations()
}
class RequestNewLocation(private val locationsRepository: LocationsRepository) {
operator fun invoke(): List<Location> = locationsRepository.requestNewLocation()
}
La capa de framework
Esta será parte del módulo app, y principalmente implementará las dependencias que proporcionamos a las demás capas. En nuestro caso particular, será LocationPersistenceSource y DeviceLocationSource.
La primera podría implementarse con Room, por ejemplo, y la segunda con el LocationManager. Pero, con el propósito de hacer esta explicación más simple, utilizaré implementaciones falsas. Puede que haga la implementación real al final, pero solo añadiría complejidad a la explicación, así que prefiero que lo olvides por ahora.
Para la persistencia, estoy usando una implementación simple en memoria:
class InMemoryLocationPersistenceSource : LocationPersistenceSource {
private var locations: List<Location> = emptyList()
override fun getPersistedLocations(): List<Location> = locations
override fun saveNewLocation(location: Location) {
locations += location
}
}
Y un generador aleatorio para la otra:
class FakeLocationSource : DeviceLocationSource {
private val random = Random(System.currentTimeMillis())
override fun getDeviceLocation(): Location =
Location(random.nextDouble() * 180 - 90,
random.nextDouble() * 360 - 180, Date())
}
Piensa en esto en un proyecto real. Gracias a las interfaces, durante la implementación de una nueva característica, puedes proporcionar dependencias falsas mientras trabajas en el resto del flujo, y olvidarte de los detalles de implementación hasta el final.
Esto también demuestra que estos detalles de implementación son fácilmente intercambiables. Así que tal vez tu App pueda comenzar inicialmente con una persistencia en memoria, y luego pasar a una persistencia almacenada. Eso se puede implementar como queramos y luego reemplazar.
Imagina que aparece una nueva biblioteca brillante (como Room 😂) y quieres probarla y considerar migrar. Solo necesitas implementar la interfaz usando la nueva biblioteca, reemplazar la dependencia, y eso es todo!
Y, por supuesto, esto también ayuda en las pruebas, donde podemos reemplazar esos componentes por componentes falsos o simulados.
La capa de presentación
Y ahora podemos escribir la UI. Para este ejemplo, estoy usando MVP, porque este artículo se originó por las preguntas en mi artículo original sobre MVP, y porque creo que es más fácil de entender que usando MVVM con componentes de arquitectura. Pero ambos enfoques son muy similares.
Primero, necesitamos escribir el presentador, que recibirá una dependencia de View (la interfaz del presentador para interactuar con su vista) y los dos casos de uso:
class MainPresenter(
private var view: View?,
private val getLocations: GetLocations,
private val requestNewLocation: RequestNewLocation
) {
interface View {
fun renderLocations(locations: List<Location>)
}
fun onCreate() = launch(UI) {
val locations = bg { getLocations() }.await()
view?.renderLocations(locations)
}
fun newLocationClicked() = launch(UI) {
val locations = bg { requestNewLocation() }.await()
view?.renderLocations(locations)
}
fun onDestroy() {
view = null
}
}
Todo bastante simple aquí, aparte de la forma de hacer las tareas en segundo plano. Estoy usando corutinas. No estoy seguro de si es la mejor decisión, porque quería mantener este ejemplo lo más simple posible. Así que házmelo saber en los comentarios si no lo entiendes. Ya hablé de corutinas en Kotlin 1.3 en este blog si te interesa.
Finalmente, MainActivity. Para evitar usar un inyectror de dependencias, declaré las dependencias aquí:
private val presenter: MainPresenter
init {
// Esto se haría por un inyectador de dependencias en una App compleja
//
val persistence = InMemoryLocationPersistenceSource()
val deviceLocation = FakeLocationSource()
val locationsRepository = LocationsRepository(persistence, deviceLocation)
presenter = MainPresenter(
this,
GetLocations(locationsRepository),
RequestNewLocation(locationsRepository)
)
}
No recomendaría esto para una App grande, porque no podrías reemplazar las dependencias en las pruebas de UI, por ejemplo, pero es suficiente para este ejemplo.
Y el resto del código no necesita mucha explicación. Tiene un RecyclerView y un Button. Cuando se hace clic en el botón, llama al presentador para que solicite una nueva ubicación:
newLocationBtn.setOnClickListener { presenter.newLocationClicked() }
Y cuando el presentador termina, llama al método de View. Esta interfaz es implementada por la actividad de esta manera:
override fun renderLocations(locations: List<Location>) {
locationsAdapter.items = locations
}
Modelos de capa y transformaciones de datos
Como mencioné anteriormente, no me gusta crear modelos para todas las capas solo por defecto. Pero para mí, la presentación puede ser un buen lugar donde podríamos hacer uso de este concepto.
Como viste en el código del adaptador, hice algunos cálculos complejos para convertir el modelo de dominio en lo que queremos ver en la pantalla. Eso se puede simplificar usando un modelo específico:
data class Location(val coordinates: String, val date: String)
Y luego, podemos convertir el modelo de dominio en el modelo de presentación. En este caso, estoy usando una función de extensión que se aplica a la ubicación de dominio. Recuerda que, gracias a las importaciones nombradas, podemos cambiar el nombre de las clases cuando tenemos dos que se llaman igual:
import com.antonioleiva.domain.Location as DomainLocation
...
fun DomainLocation.toPresentationModel(): Location = Location(
"${latitude.toPrettifiedString()} | ${longitude.toPrettifiedString()}",
date.toPrettifiedString()
)
Después de esto, la transformación en el presentador es realmente fácil:
view?.renderLocations(locations.map(DomainLocation::toPresentationModel))
Y finalmente, el adaptador se ve mucho más simple:
fun bind(location: Location) {
with(location) {
locationCoordinates.text = coordinates
locationDate.text = date
}
}
De esa manera, evitamos hacer transformaciones de datos en las clases de UI, lo que reduce la complejidad.
Conclusión
¡Así que eso es todo! Lo básico de la arquitectura limpia es de hecho bastante simple.
Solo necesitas entender cómo funciona la inversión de dependencias, y luego enlazar las capas correctamente. Solo recuerda no añadir dependencias a los módulos externos desde los internos, y tendrás una excelente ayuda de la IDE para hacerlo bien.
Sé que esto es mucha información. Pero mi objetivo es que esto sirva como un punto de entrada para las personas que nunca vieron la arquitectura limpia antes. Así que si aún tienes dudas, házmelo saber en los comentarios y reescribiré este artículo tantas veces como sea necesario.
Y también recuerda que para hacer este artículo simple, he omitido algunas complejidades que encontrarías en una arquitectura limpia regular. Una vez que tengas esto asentado, te sugiero que leas ejemplos más completos. Siempre me gusta recomendar este de Fernando Cejas.
El enlace al repositorio de Github está aquí. Ve allí para revisar los detalles, y si te gusta, por favor muéstralo con una estrella 🙂
¡Feliz codificación!