· ai · 10 min read
How I Built an Autonomous Development System with AI Agents

I’ve been experimenting with something that had me curious: letting AI develop a software project almost entirely on its own.
I’m not talking about asking it to generate a function or a component. I’m talking about a system of agents that scan the code, detect problems, create issues, prioritize them, implement fixes, push commits, and close the issues. All without human intervention.
The project is Learnfolx (final name TBD 😄), a B2B training platform I’m building (Next.js + PostgreSQL + Prisma + Redis). And the AI has been working relentlessly: 80 issues created and ~50 closed in 3 days. Without me writing a single line of code.
Here’s how I set it up, with all the prompts so you can replicate it:
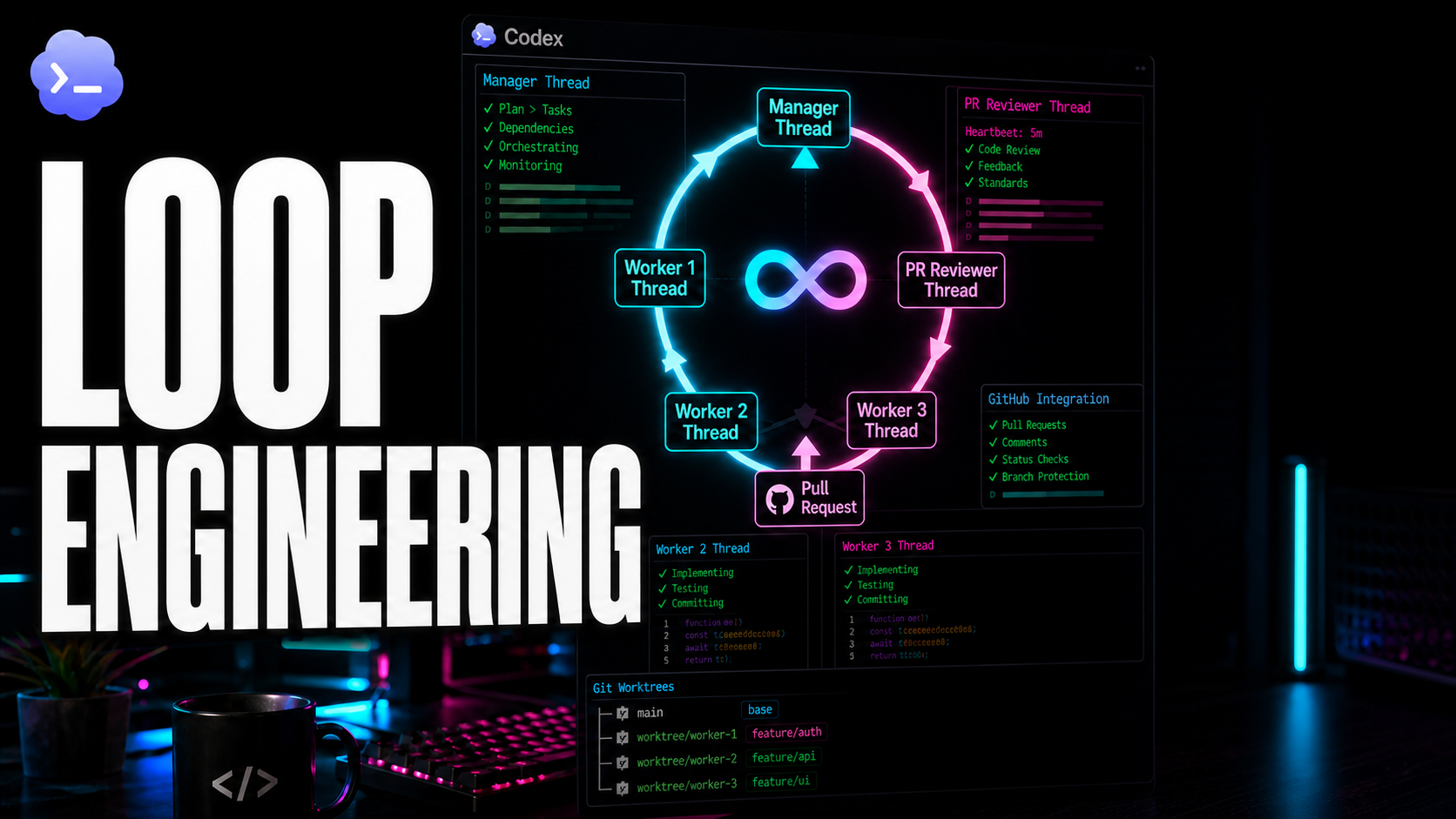
The architecture: scanners + triage + executor
The system has 3 layers:
- Scanners — Specialized agents that analyze the code looking for a specific type of problem. Each one creates GitHub issues with their findings.
- Triage — A daily cron that automatically prioritizes new issues (p1/p2/p3).
- Executor — An agent that every hour picks the highest priority issue, implements it, passes checks, and closes it.
And there’s a fourth layer that acts as a safety net:
- Smoke tests — Every 4 hours, verifies the project compiles, passes tests, and has no regressions.
Everything runs on Codex App automations + an external cron for triage (though that could also be in Codex).
Don’t let this put you off if you don’t use Codex: any process that can run cron tasks would work the same way.
The scanners: 6 specialists
Here’s how I organized them. This was actually quite interesting, because configuring all of this manually would have been tedious. Instead, I asked my Telegram chatbot (a simple OpenClaw-like tool) that I wanted to set this up.
Together we defined the scanners, and it automatically inspected the Codex configuration at ~/.codex, figured out how automations are configured, and set them up on its own.
1. Security Scanner (daily, 9:00)
The security scanner combines deterministic tools with LLM review. It runs Semgrep and npm audit first, then does a manual review looking for things the tools don’t cover.
You are a security scanner. Your ONLY job is to detect problems
and create GitHub issues. DO NOT implement anything.
## Step 1: Semgrep (static analysis)
Run semgrep with automatic rules:
semgrep --config auto --json --quiet .
Analyze the JSON results. Group by severity and vulnerability type.
## Step 2: npm audit
Run pnpm audit --json to detect vulnerable dependencies.
## Step 3: Complementary manual review
Analyze the project looking for things semgrep doesn't cover well:
- Hardcoded secrets or API keys in the code
- Endpoints without proper authentication/authorization
- Sensitive environment variables exposed
- Insecure configurations (CORS, headers, etc.)
- Incorrect authorization logic (e.g., tenant isolation bypass)
Real result: It detected hardcoded credentials in the seed script (only for development, but still), a CVE in the qs dependency, and a CORS exposure in the esbuild dev server.
2. Architecture Scanner (daily, 13:00)
Uses madge to detect circular dependencies and knip for dead code, plus LLM review for oversized files or long functions.
## Step 1: Circular dependencies (madge)
Run:
npx madge --circular --extensions ts,tsx apps/web/src/
## Step 2: Dead code (knip)
Run:
npx knip --no-progress
## Step 3: Complementary manual review
- Duplicated code across files
- Files that are too large (>300 lines)
- Functions that are too long (>50 lines)
- Inconsistent patterns
- Components with too many responsibilities
- Pending TODOs and FIXMEs
Real result: Found 19 tech debt issues, from 600+ line services to CSS duplicated across 8 admin modules.
3. Test Scanner (daily, 11:00)
Runs vitest --coverage and analyzes real coverage, prioritizing critical modules.
## Step 1: Real coverage (vitest)
Run:
pnpm vitest run --coverage --reporter=json
Analyze which files have low (<50%) or zero coverage.
Prioritize files in src/lib/services/, src/app/api/, and src/lib/auth/.
## Step 2: Failing tests
## Step 3: Complementary manual review
- Critical functions without tests (auth, payments, data access, tenant isolation)
- Flaky tests or tests with unmocked external dependencies
- API endpoints without integration tests
4. Performance Scanner (daily, 15:00)
Looks for N+1 queries, unmemoized components, large bundles, and redundant API calls.
You are a performance scanner. Your ONLY job is to detect
performance problems and create GitHub issues. DO NOT implement anything.
Analyze the project looking for:
- N+1 queries in Prisma or inefficient database access
- React components without memoization that should have it
- JavaScript bundles that are too large
- Unoptimized images or missing lazy loading
- Unnecessary renders
- Missing cache on endpoints that need it
- Redundant or cascading API calls
Real result: Detected 4 performance issues, including N+1 queries in the analytics dashboard and individual lookups per row in CSV import.
5. DX Scanner (daily, 17:00)
Combines static analysis tools with manual review to detect development friction.
## Step 1: Dead code and unused dependencies (knip)
Run:
npx knip --no-progress
## Step 2: Type checking
Run:
pnpm tsc --noEmit
Review type errors that aren't visible in the IDE but break the build.
## Step 3: Outdated dependencies
Run:
pnpm -r outdated
## Step 4: Complementary manual review
- Unresolved linting errors
- Missing or broken package.json scripts
- Outdated or missing documentation
- Incomplete .gitignore
Real result: Detected that tsc wasn’t accessible as a command, that knip couldn’t load the config, and several dependencies with pending major versions (Prisma 7, Vitest 4, Zod 4).
6. Feature Scanner (daily, 14:00)
This is the most interesting one. It reads the project specifications (business rules, milestone capabilities, entities) and compares them with the current code to detect functionality that should exist but isn’t implemented.
You are a feature scanner. Your ONLY job is to detect
improvements and new features and create GitHub issues. DO NOT implement anything.
Process:
1. Read the specs: docs/domain/business-rules.md,
docs/domain/milestone-capabilities.md,
docs/domain/entities-and-invariants.md
2. Read docs/architecture/overview.md and docs/design/navigation-map.md
3. Review the current code and compare it with the specs
Look for:
- Functionality specified in docs that isn't implemented or is incomplete
- User flows missing validations, feedback, or error states
- Partially implemented features
- Obvious UX improvement opportunities
- Data that's collected but not displayed
- Uncovered edge cases in critical flows
Real result: Detected that student evaluations had no submission flow, that student progress wasn’t shown in the UI, and that FUNDAE exports were mocks.
The throttle: keeping things under control
An important lesson: on the first day, the scanners created 26 issues because they were doing the initial sweep of the entire repo. To prevent the queue from spiraling out of control, each scanner has a throttle:
Before creating issues, count how many open issues exist with
label [type]. If there are 10 or more, DO NOT create new issues and stop.
Exception: critical security vulnerabilities are always created, regardless of the throttle.
Automatic triage
A daily cron at 10:00 reviews all unprioritized issues and classifies them automatically:
- p1: active vulnerabilities (CVE), missing core functionality, blocking bugs
- p2: performance improvements, useful features, tests for critical modules
- p3: refactors, minor improvements, low-frequency optimizations
The key is that it assigns labels directly, it doesn’t just recommend. I only override if I disagree with a priority.
It also generates a daily summary with created issues, closed issues, commits, and smoke test status.
The executor: the one that does the work
This is the heart of the system. It runs every hour and picks the highest priority issue to implement.
Selection process (priority > type > age):
1. Look for p1 issues. If found, select by type order.
2. If no p1, look for p2. If found, select by type order.
3. If no p2, look for p3.
4. If no issues with priority, do nothing.
Type order within the same priority level:
1. security (vulnerabilities first)
2. bug (functional errors)
3. feature (new or incomplete functionality)
4. performance (optimization)
5. tests (coverage)
6. architecture (refactors)
7. dx (developer experience)
Important detail: features come before refactors at the same priority level. I don’t want the agent spending the day splitting files into pieces when there’s real functionality pending.
The executor works directly on main (no PRs), runs lint + typecheck + tests before each commit, and automatically closes the issue with a commit reference.
The safety net: smoke tests
Every 4 hours, an independent agent verifies everything still works:
pnpm buildpnpm typecheckpnpm testpnpm lint- Verifies that recent commits properly closed their issues
If something fails, it creates an issue with bug, p1 labels — and the executor picks it up in the next iteration. Regressions are always top priority.
It logs each run in docs/smoke-log.md for traceability.
Real result: On the first day, the smoke test detected 7 chain regressions. The executor fixed them automatically one after another.
The numbers
In 3 days of operation:
- ~80 issues created by the scanners
- ~50 issues closed by the executor
- ~60 automatic commits
- 0 lines of code written by me
- All 5 p1 security issues were closed the same day
- Core features implemented: student evaluations, progress UI, real FUNDAE exports, Zoom attendance sync
What I’ve learned
What works well:
- The scanner/executor separation is key. The one detecting problems must NOT be the one fixing them. It avoids bias.
- Deterministic tools (Semgrep, knip, madge, vitest coverage) complement the LLM very well. The LLM catches things the tools miss, and the tools have zero false negatives for their patterns.
- The throttle is essential. Without it, the scanners drown the executor with issues faster than it can process them.
- The smoke test as a safety net works: it caught 7 regressions that the executor introduced while making concurrent changes.
What to watch out for:
- Core features (new functionality with business logic) need human review. The agent can misimplement a requirement and you won’t know unless you check.
- P3 refactors pile up. The executor always prioritizes features and bugs, so “minor” tech debt grows. You need periodic purges or a dedicated day for p3 only.
- The quality of generated tests is questionable. They cover code but sometimes the assertions are weak. Mutation testing (Stryker) would be the next step to verify that tests actually validate something.
Speed: it’s not magic, it’s your tokens
I’ve been running this for 5 days, and many of you ask how the tokens hold up. The reality is that with a $20 Codex account, you can’t sustain this pace.
In the end, you have to decide: speed vs. cost, and find a balance.
As of today, I’m managing with 2 x $20 ChatGPT (Codex) accounts, and I think they’ll still fall short. This considering that Codex App tokens are currently doubled.
So to take this seriously and maintain good speed, the $200 account seems pretty much necessary.
Is this the future?
Spotify just published that their best developers haven’t written code since December, thanks to tools like Claude Code and their internal system Honk. My experiment is much more modest, but points in the same direction: the developer’s role shifts from writing code to orchestrating agents.
I don’t think we’re ready to let this run unsupervised on critical projects. But for a side project or an early product stage, the speed is absurd. 3 days of autonomous work equals what would have taken me weeks to do manually.
If you want to replicate this, the prompts are exactly what I’ve shared here. If you try it, let me know how it goes.